Transformers FLOPS and memory usage
Understanding memory usage and the number of floating point operations required to run inference using Transformers
Introduction
Everyday we hear of new AI models that are larger and better than ever before. As of writing this post, the state-of-the-art models have hundreds of billions of parametersDeepSeek R1 has about 671 billion parameters. How much GPU memory is needed to run this model? How long will inference take on a given GPU? In this post, I will walk through an example to understand how to calculate memory usage and estimate the time taken to run inference. This post assumes familiarity with the transformerhttps://arxiv.org/pdf/1706.03762 architecture.
In the first part of this post, I count all the floating point operations that happen during the forward pass. Why is this important? Every GPU has a maximum number of floating point operations it can perform in a second (FLOPS) and is specified in the GPU specs. If we can calculate the number of floating point operations that our model needs to perform for a single token, we can calculate the time taken for the forward pass.Assuming that we have a kv cache, I’m calculating the FLOP for a single new token. More details about this later in the post.
In the second part of this post, I calculate the GPU memory usage given a model. This includes the memory needed to store the model parameters and kv cache.
Floating point operations
Given a transformer model and a GPU, can we approximately calculate the inference time without running any code? We can calculate it using this simple formula
where
In the next few sub-sections, I go through in detail as to how I arrived at the above equation. Feel free to skip to the memory section if you aren’t particularly interested in the details.
A GPU datasheet specifies the theoretical maximum number of floating point operations it can perform in a second. Using the transformer model architecture, let’s calculate the number of floating point operations (FLOP) per token
FLOP for matrix multiplication
Let’s consider an example for matrix multiplication Lecture Notes on FLOPS for basic operations
A is a matrix and B is a matrix. The product of A and B will have elements. In the generalized case, when a matrix of dimensions is multiplied with a matrix of dimensions , the product is a dimensional matrix.
Calculating the first element of the ,
Notice that there are 3 multiplication operations and 2 addition operations. In the general case, there are additions and multiplications to calculate one element in the product matrix.
Since there are 8 elements in and elements in the general case, the total number of floating point operations to calculate the product of two matrices is
FLOP in a transformer block
A transformer block consists of two sub-blocks, a multi-headed attention block and a feed forward block which are shown in the picture below.
Let’s calculate the number of floating point operations in each of the steps in the transformer block.
Note that typically
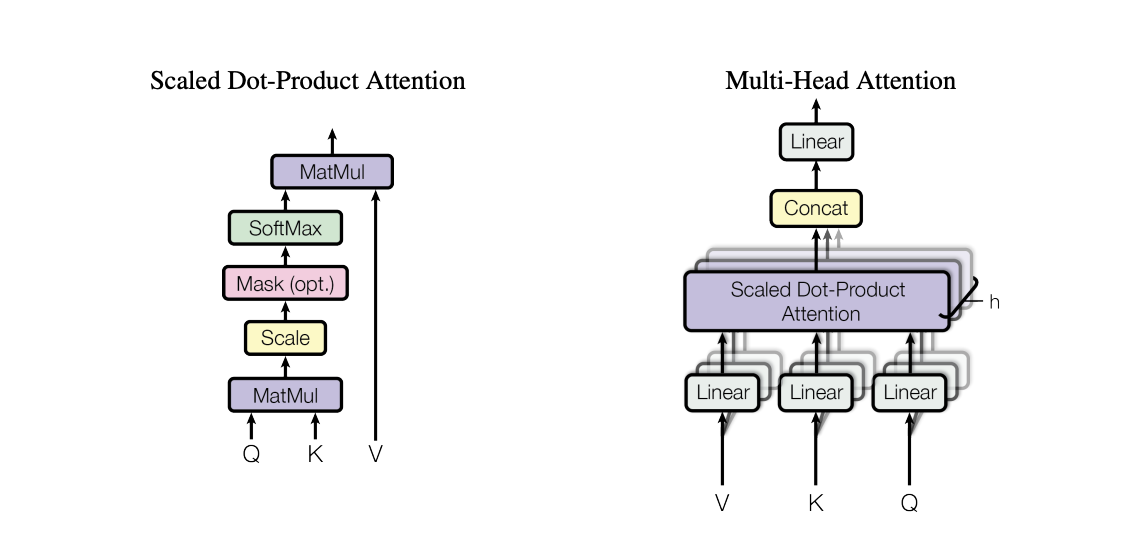 Image Courtesy: Attention is all you need
Image Courtesy: Attention is all you need
For a single token, the first step is calculating the keys, queries and values for all the attention head.
The number of floating point operations to calculate q using (1) is
The same number of FLOP are required to calculate k and v. Using (2), the total FLOP count per head is
With all the heads combined, the total FLOP count is
Scaled dot product attention is calculated using
Concatenation does not involve any matrix multiplications. The output of the concatenation is a vector. The linear layer is a matrix. Based on (1), the number of FLOP in the linear layer is Assuming the linear layers have zero bias. Even if they don’t, they will not contribute significantly to the FLOP count
The feed-forward layer consists of two linear layers. The first layer is a matrix and the second layer is a matrix. Therefore the number of FLOP in these layers are
Adding (3),(4),(5) and (6), the total FLOP in a transformer block is
When is sufficiently large, term dominates, so we can ignore all the terms with the coefficient. Note that I have ignored the layernorm calculation and the residual calculation. These calculations would also be a constant factor times and will be sufficiently small.
FLOP for other layers
The transformer model consists of token embedding, position embedding, of transformer blocks and a final linear layer which has parameters. Token and position embeddings are lookups, so there is no matrix multiplication. The number of FLOP in the final linear layer is
FLOP for the full model
The transformer model has number of transformer blocks. Putting together (7) and (8), the total FLOP is
To get an idea of the scale of FLOP required to do the forward pass in a transformer using (9), I calculated the FLOP count for a few models.
My Nvidia 3060 GPU can theoretically do 101TTom’s Hardware page FLOPS using FP16 (half precision). If I run inference on the Llama 8B model, I can process about tokens per second.Note that I have not considered memory to store these parameters
Memory requirements
In a transformer model, two major components that take up the GPU memory are the model parameters and KV cache. The formula to calculate the memory usage is
where
In the following sub-sections, I will show how I arrived at this formula.
Model parameters
Typically we store all the parameters in half precision(FP16), each parameter requires 2 bytes. If a model has parameters, the memory required to store them is simply bytes
KV Cache
Let’s first understand why KV cache is necessary. In an autoregressive model like GPT-2, the next token depends on the previous tokens. Attention is calculated using the formula
, and are matrices of dimensions , is the length of the sequence. Notice that the computation increases quadratically with the length of the sequence. KV cache explained The key and value calculations are repeated for all the previous tokens which is wasteful. Caching keys and values will make the computation linear with the length of the sequence .
Let’s calculate how much memory is required to cache a single token.
Using (10), the memory needed to store 1000 tokens for a few models are shown below
On my Nvidia 3060 GPU, using GPT2, I can cache about tokens. The memory used for kv cache increases linearly with both and embedding size.