Retrieval Augmented Generation
Building a RAG pipeline using BERT and GPT-2
Introduction
What is retrieval augmented generation?
It is a paradigm where large language models (LLMs) answer queries based on certain context and reference documents. RAG is akin to a reading comprehension task, where models rely on external documents for answers, as opposed to generative models, which answer questions from memory. It is widely used in applications such as customer support chatbots and knowledge retrieval systems.
An overview of the RAG pipeline is shown in the figure below.
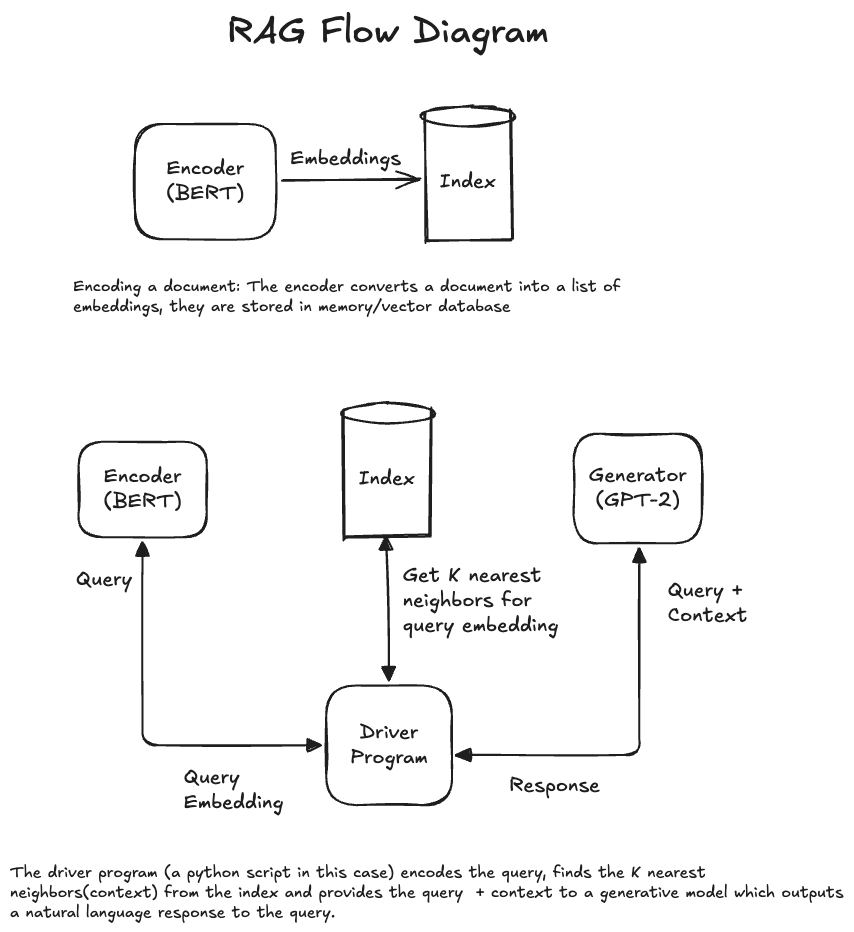
Skip to the end if you want to see the demo!
The RAG pipeline consists of mainly 4 steps:
- Encoding Knowledge: In this step, convert reference documents (Eg: A chapter from a textbook, blogpost) into dense embeddings using a language representation model like BERT. More specifically, an embedding is created for N(2–3) overlapping sentences in the document. Sentences that mean something similar should be nearby in this embedding space and sentences that are completely unrelated to each other must be far away from each other in this embedding space.
- Index: Create an index that stores vectors(embeddings) and exposes functions to quickly find the neighbors using a distance measure.
- Retrieval: Given a query, convert it into an embedding and find the “K” nearest neighbors (most relevant to the query). If the reference document is 10 pages long for example, this step will find the top K (5) sentences in the document that might answer the query.
- Generation: Using the retrieved sentences and the query, answer the query using a generative model like GPT-2
Goal
Create an end-to-end working RAG pipeline with small models with focus on inference speed and training speed so I can run the experiments quickly on my NVDIA GeForce GTX 1080 8GB GPU. All the code is on my github repo. I have jupyter notebooks, so it should be easy to reproduce these results.
Let’s go through the steps to create a RAG from scratch
Encoding knowledge
In this context, a sentence refers to a contiguous sequence of words or characters.A sentence is a point represented by N-Dimensional vector i.e., any given sentence is represented by N floating point numbers. How do we come up with these N numbers for a sentence?
BERT
Bidirectional Encoder Representations from Transformers is a language representation model. For each sentence, as shown in the figure below
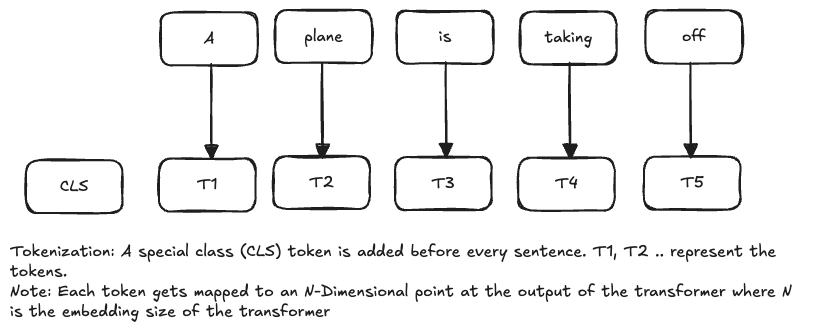
A special CLS token is added at the beginning of the sentence. As the tokens go through the different layers of the transformer, their position in N-dimensional space is modified by tokens that appear before and after the current token within the context window size. 3Blue1Brown’s video explains this very nicely.
The last attention layer of the transformer has an N-dimensional embedding for each of the tokens in the input sentence including the CLS token. One way to represent an entire sentence with a single embedding could be by using the embedding for the CLS token. Another way could be by averaging all the embeddings for the sentence.
The BERT model, when finetuned on NLI tasks has shown impressive performance. However, to compare two sentences, they both must be input to the model at the same time with a special separator token [SEP] in between the two sentences. To check if a query is close to sentences in a document, we would have to run the BERT model M times for each query where M is the number of embeddings in the index. If a document contained 60k embeddings and model inference took 100ms, to answer a single query would take 1 hour and 40 minutes. This makes it unusable.
Sentence BERT
Sentence-BERT showed that the embeddings from pre-trained BERT did poorly on semantic similarity tasks. They outlined a procedure to fine-tune BERT. The fine-tuned embeddings perform significantly better than the pre-trained BERT embeddings when calculating cosine similarity. Assuming that the embeddings for the document have already been calculated, for 60k embeddings, the K nearest neighbors can be found within 5 seconds(100ms to encode the query, ~4s to get the cosine distance from embeddings in the index).
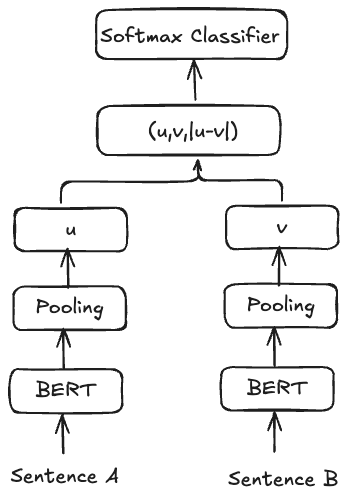
Image Source: https://arxiv.org/pdf/1908.10084
The architecture of Sentence BERT is as shown in the figure above. Sentences A(Embedding u) and B(Embedding v) are passed through the same network. The two embeddings u, v and absolute difference abs(u-v) is concatenated and a fully connected layer is used for classification. The NLI(Natural Language Inference) task is a 3 way classification task - Given two sentences, classify whether the second sentence is
- Contradiction : The opposite of the first sentence.
- Entailment: A continuation of the first sentence.
- Neutral: Not related to the first sentence.
Natural Language Inference Tasks
As suggested in the paper, I combined Stanford Natural Language Inference dataset and MNLI to finetune Sentence BERT. There are a total of 1M samples with these two datasets combined. The code for this dataset is here
| Dataset | Test Accuracy(%) |
|---|---|
| SNLI | 82.24 |
| Multi NLI | 73.08 |
Based on the benchmarks for SNLI and MultiNLI, the performance of my fine-tuning seems about right.
Semantic Textual Similarity Tasks(STSb)
The goal of fine-tuning BERT is to make the embeddings for similar sentences to be “nearby” in a high dimensional space. The STS dataset consists of pairs of sentences and a score associated with it. The score is a number between -1 and 1. 1 implies that the sentences are similar, -1 means they are contradictory and 0 means they are unrelated.
| Model | Spearman’s Rank Correlation coefficient |
|---|---|
| BERT - CLS embedding | 0.2030 |
| Avg BERT Embeddings | 0.4693 |
| SBERT pretrained on SNLI | 0.7057 |
| SBERT pretrained on SNLI + MultiNLI | 0.7462 |
The code to reproduce these results is here
Index
I used FAISS library. It stores the embeddings in an matrix in memory. During retrieval, the K nearest sentences (by L2 distance) to the query are retrieved.
Retrieval
Suppose we have to read a long document and answer questions based on this document. After reading the question, we usually take a look at the document again to find what part of the document might contain the answer to the question.
For example, let’s say our document is as follows
New Delhi is the capital city of India. It has a population of about 33 million.
and the query is
What is India's capital city?
We know that the first sentence in our document is the most relevant to the query. The distance between the query and the first sentence should be smaller than the distance between the second sentence and the query.
In the retrieval step, the query is encoded and the K closest sentences to the query are returned.Link to code
Generation
GPT-2 was trained using the Language Modeling objective, i.e given a list of words, predict the most probable next word. Initial attempts with pre-trained GPT-2 in the RAG pipeline resulted in incoherent outputs, likely due to its lack of specialized training for question answering tasks.
Fine-tune GPT-2 using SQuAD
I fine-tuned the last 4 layers of GPT-2 using the Stanford Question Answering Dataset. The dataset contains reading comprehension tasks - it has a paragraph or so of context and questions and answers based on that paragraph.
Putting it all together - Build an end-to-end RAG pipeline
Using the fine tuned BERT model (sentence BERT) for creating embeddings and the fine-tuned GPT-2, I built a RAG. The sentence BERT model creates embeddings for the document and adds to an index. When there is a query, the query is converted into an embedding using the same BERT model and the 5 nearest neighbors to the query embedding are retrieved.
As a final step, the 5 nearest neighbors are provided as context in addition to the query and GPT-2 generates a response.
Pre-processing: Before running Sentence BERT, I split the document into sentences. Each embedding represents 2 sentences, and consecutive embeddings have a 1 sentence overlap. For example, let’s say my document looks like this
New Delhi is the capital city of India. It has a population of over 33 million. The winters there are cold and the summers are extremely hot.
New Delhi is the capital city of India. It has a population of 33 million. -> embedding
It has a population of 33 million. The winters there are cold and the summers are extremely hot. -> embedding
For the demo, I copied all the text from the Tour De France wikipedia page and used that as the knowledge base. I asked a few questions about the Tour De France and got responses from the RAG pipeline.
Query: Who was the first British rider to win the Tour de France?
Response: Bradley Wiggins
Query: How many stages has Mark Cavendish won?
Response: 35th overall.
Query: What color jersey does the winner of the general classification wear?
Response: Yellow jersey
Results
For all my experiments, I used the pre-trained BERT base model (124M parameters) and GPT-2 (124M parameters). The RAG demo shows questions answered reasonably correctly. There were questions for which GPT-2 gave factually incorrect and sometimes completely irrelevant answers.